

Qualitative Results on Real-world Images

Pre-trained diffusion models provide rich multi-scale latent features and are emerging as powerful vision backbones. While recent works such as Marigold and Lotus adapt diffusion priors for dense prediction with strong cross-domain generalization, their potential for structured outputs (e.g., human pose estimation) remains underexplored. In this paper, we propose SDPose, a fine-tuning framework built upon Stable Diffusion to fully exploit pre-trained diffusion priors for human pose estimation. First, rather than modifying cross-attention modules or introducing learnable embeddings, we directly predict keypoint heatmaps in the SD U-Net’s image latent space to preserve the original generative priors. Second, we map these latent features into keypoint heatmaps through a lightweight convolutional pose head, which avoids disrupting the pre-trained backbone. Finally, to prevent overfitting and enhance out-of-distribution robustness, we incorporate an auxiliary RGB reconstruction branch that preserves domain-transferable generative semantics. To evaluate robustness under domain shift, we further construct COCO-OOD, a style-transferred variant of COCO with preserved annotations. With just one-fifth of the training schedule used by Sapiens on COCO, SDPose attains parity with Sapiens-1B/2B on the COCO validation set and establishes a new state of the art on the cross-domain benchmarks HumanArt and COCO-OOD. Furthermore, we showcase SDPose as a zero-shot pose annotator for downstream controllable generation tasks, including ControlNet-based image synthesis and video generation, where it delivers qualitatively superior pose guidance.
| Model | Pre-trained Backbone |
Parameters | Input size | Train dataset |
Train epochs |
AP | AR |
|---|---|---|---|---|---|---|---|
| Sapiens-1B | Sapiens ViT | 1.169B | 1024 × 768 | COCO | 210 | 82.1 | 85.9 |
| Sapiens-2B | Sapiens ViT | 2.163B | 1024 × 768 | COCO | 210 | 82.2 | 86.0 |
| GenLoc | Stable Diffusion-v1.5 | 0.95B | N/A | COCO | 14 | 77.6 | 80.7 |
| ViTPose++-H | ViTAE | 0.63B | 256 × 192 | Mixture* | 210 | 79.4 | N/A |
| SDPose (Ours) | Stable Diffusion-v1.5 | 0.95B | 1024 × 768 | COCO | 40 | 81.2 | 85.3 |
| SDPose (Ours) | Stable Diffusion-v2 | 0.95B | 1024 × 768 | COCO | 40 | 81.3 | 85.2 |
* Mixture includes COCO, AIC, MPII, AP10K, APT36K, and WholeBody datasets.

Comparison on Stylized Paintings: Sapiens Whole-Body vs. SDPose Whole-Body. All erroneous predictions are highlighted with yellow boxes. SDPose yields fewer false positives and notably better facial keypoint localization.
To complement the HumanArt dataset and enable OOD evaluation under matched content and labels, we construct COCO-OOD by applying artistic style transfer to the original COCO images. We adopt the official StyTR2 and CycleGAN framework to perform unpaired image-to-image translation from the COCO domain (natural photographs) to the target domain of Ukiyo-e and Monet-style paintings. During conversion, all validation images in COCO are processed to produce style-transferred counterparts, while preserving their original human annotations (bounding boxes, keypoints). This yields an OOD variant of COCO in which the underlying scene structure is unchanged, but the texture, color palette, and brushstroke patterns are consistent with artistic style. Importantly, for fair comparison and to avoid introducing priors from large-scale pretrained diffusion models, we intentionally adopt the earlier StyTR2 and CycleGAN framework rather than more recent style transfer methods. Such stylization introduces a significant appearance shift while keeping pose-related geometric information intact, making it suitable for robust pose estimation evaluation.

COCO-OOD Dataset Visualization. A 5×10 grid showing 50 randomly sampled images from the COCO-OOD dataset, demonstrating the diversity of Monet-style oil painting transformations applied to COCO validation images.

COCO-OOD visualizations with Monet-style oil painting. We use CycleGAN to stylize COCO validation images into a Monet-like oil painting domain, creating an OOD split to evaluate pose estimation robustness under appearance shift.
| Model | Pre-trained Backbone |
Parameters | Train epochs |
HumanArt | COCO-OOD | ||
|---|---|---|---|---|---|---|---|
| AP | AR | AP | AR | ||||
| Sapiens-1B | Sapiens ViT | 1.169B | 210 | 64.3 | 67.4 | 58.8 | 63.3 |
| Sapiens-2B | Sapiens ViT | 2.163B | 210 | 69.6 | 72.2 | 59.6 | 64.0 |
| GenLoc | Stable Diffusion-v1.5 | 0.95B | 14 | 67.0 | 70.8 | N/A | N/A |
| SDPose (Ours) | Stable Diffusion-v2 | 0.95B | 40 | 71.2 | 73.9 | 63.5 | 68.2 |
All models are trained on COCO with an input size of 1024 × 768; full HumanArt results for other methods are in the supplementary.
For human or humanoid character generation, an accurate skeleton is essential for transferring poses between characters. Traditional pose estimators often fail to precisely capture the skeletons of art-based human or humanoid characters. Our method provides a generalizable pose estimation approach that can benefit animation production. As shown in the figure below, we compare ControlNet outputs using DWPose as the baseline pose annotator. Notably, our SDPose yields more precise and detailed skeletons than DWPose, enabling reliable pose transfer and high-quality image generation for artistic characters.

Visualization of pose-guided image generation results. The lower images illustrate results from the baseline, which combines a pre-trained ControlNet with the DWPose estimator. In comparison, the upper images show results obtained using our SDPose as the pose annotator. Yellow boxes highlight baseline failures. Prompts, random seeds, and other settings are kept identical for fairness.
Recent advances in controlled video generation have gained significant traction. Despite the progress of video generation models in producing higher-quality outputs, extracting reliable control conditions remains critical for achieving high-quality results. As shown in the figure below, our SDPose provides more accurate poses for the driving frames, enabling more reliable pose-sequence transfer from animations to animations. Video frames are generated by Moore-Animated Anyone.

Qualitative comparison for pose-controlled video generation in the wild. The first row shows the source image and frames from the driving video. The second row shows output video frames generated from the pose sequence estimated by the baseline model DWPose, while the third row shows the results guided by our SDPose. Red boxes highlight failures in the generated video, and yellow boxes highlight errors in pose estimation.
In this paper, we directly leverage the multi-scale latent features of SD U-Net for the pose estimation task. The input image is encoded by the frozen SD-VAE encoder and then fed into the SD U-Net, from which we extract multi-scale features at the upsampling stage. These features serve as robust representations for downstream applications.
Stable Diffusion's U-Net outputs a 4-channel latent for the VAE through a single convolutional layer. In contrast, pose estimation requires K-channel heatmaps with K ≫ 4, making the 4-channel latent a severe information bottleneck. To address this, we replace the original 4-channel head with a lightweight heatmap decoder. The decoder consists of a deconvolution layer for upsampling, followed by two 1×1 convolutions that output K-channel heatmaps. This modification removes the bottleneck and shortens the supervision path to keypoints.
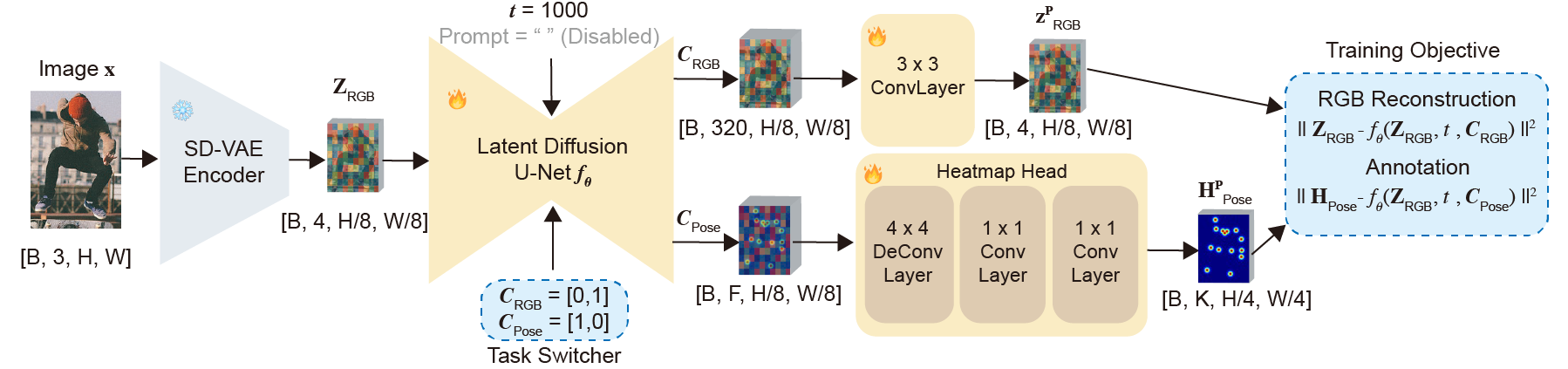
Training Pipeline of SDPose. The input RGB image is first encoded into the latent space by a pre-trained VAE. The U-Net is conditioned for multi-task learning via a class embedding. When the class label is set to [0,1], the U-Net predicts the reconstructed RGB latent; when set to [1,0], it produces features for heatmap prediction. The output layer of the U-Net is task-specific: the original convolutional output layer is retained for RGB latent reconstruction, while a lightweight heatmap decoder is used to process the U-Net's intermediate features for keypoint heatmap prediction.
To preserve the fine-detail representation capability of diffusion priors and to avoid overfitting to the pose estimation domain, we adopt the Detail Preserver strategy. Concretely, we introduce a class embedding C ∈ {CRGB, CPose} that controls the behavior of the denoising U-Net fθ. When CRGB is provided, the network is trained to reconstruct the RGB latent zRGB; when CPose is provided, it learns to reconstruct the ground-truth heatmap HPose. The overall objective is:
L = ||zRGB - fθ(zinput, t, CRGB)||² + ||HPose - fθ(zinput, t, CPose)||²
where zinput is the latent encoded from the input image by the SD-VAE, and t is fixed to t=1000 in our experiments.
The input RGB image x is encoded by the SD-VAE into the latent representation zRGB. The latent diffusion U-Net then performs a single-step regression with the timestep fixed at t = 1000, using the class label CPose to execute the pose estimation task. The text condition is disabled by feeding an empty text embedding to the U-Net.

SDPose Inference Pipeline. The input RGB image is encoded by the SD-VAE into the latent representation. The latent diffusion U-Net then performs a single-step regression with the timestep fixed at t = 1000, using the class label CPose to execute the pose estimation task. The text condition is disabled by feeding an empty text embedding to the U-Net.
@misc{liang2025sdposeexploitingdiffusionpriors,
title={SDPose: Exploiting Diffusion Priors for Out-of-Domain and Robust Pose Estimation},
author={Shuang Liang and Jing He and Chuanmeizhi Wang and Lejun Liao and Guo Zhang and Yingcong Chen and Yuan Yuan},
year={2025},
eprint={2509.24980},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.24980},
}